什么是robots.txt?如何配置robots.txt 及其SEO用法 | 详细指南
在进行搜索引擎优化(SEO)时,robots.txt配置是每位站长都无法忽略的环节。位于网站根目录的robots.txt是搜索引擎爬虫最先访问的文件,它用来告诉爬虫能够访问哪些页面,主要目的是管理流向你网站的爬虫数量,避免过多的抓取请求让你的服务器过载。
大橘以谷歌官方的robots指南作为参考对象,并根据SEO实操经验加工写下这篇robots.txt笔记。所以不用担心真实性和实用性的问题,这篇笔记将会手把手教你配置robots文件,没时间研究原文档的伙伴可以放心食用!
笔记概览:

什么是robots.txt
robots.txt是一个放置于网站根目录下的文本文件,用于向搜索引擎爬虫提供指令,指示哪些页面可以被抓取,哪些页面应当被忽略。它是一个网站与搜索引擎爬虫沟通的基本文件,帮助网站站长控制其网站内容的索引方式。
注意:robots.txt只对承认这份协议的搜索引擎爬虫有效,例如谷歌,必应,百度,雅虎等,对于一些抓取工具的爬虫没用。
robots.txt对网站重要吗?
如果你的网站需要以下用途,那么robots文件的配置就十分必要,反之,如果你没有限制网站抓取的需要,那就可以不用配置robots文件。
1. 优先级设置
通过robots.txt,指示搜索引擎优先抓取网站中最重要的页面。
例如:
User-agent: *
Disallow: /temp/ # 禁止抓取临时文件夹
Disallow: /test/ # 禁止抓取测试页面
Allow: /products/ # 允许抓取产品页面
这样配置后,搜索引擎爬虫将专注于抓取/products/下的重要产品页面。
2. 隐私保护
使用robots.txt来防止爬虫访问包含敏感信息的页面。
例如:
User-agent: *
Disallow: /admin/ # 禁止抓取后台管理页面
Disallow: /user/ # 禁止抓取用户个人资料页面
这可以保护包含用户隐私信息的页面不被搜索引擎公开(注意:robots只能阻止遵守协议的搜索引擎,完全阻止抓取需要使用密码保护)。
3. 内容管理
阻止搜索引擎抓取未完成或未发布的页面。
例如:
User-agent: *
Disallow: /upcoming-events/ # 禁止抓取即将举行的活动页面,直到它们准备好公开
Disallow: /drafts/ # 禁止抓取草稿文件夹
这可以确保只有完成和优化的页面才会被搜索引擎索引。
4. 避免重复内容
防止爬虫抓取多个相同或相似的页面。
例如:
User-agent: *
Disallow: /node/*?view_mode=teaser # 禁止抓取内容预览页面,避免重复
Disallow: /print/ # 禁止抓取打印版页面
这有助于减少网站内部的重复内容,提高搜索引擎的索引效率。
5. 网站结构优化
指导爬虫按照网站结构和导航逻辑来抓取页面。
例如:
User-agent: *
Disallow: /old-site/ # 禁止抓取旧版网站的页面
Allow: /new-site/ # 允许抓取新版网站的页面
这有助于搜索引擎更好地理解网站的新结构和导航逻辑。
6. 遵循网站政策
确保爬虫的行为符合网站的版权声明和使用条款。
例如:
User-agent: *
Disallow: /license-agreement/ # 禁止抓取版权声明页面,确保版权信息不被滥用
Disallow: /terms-of-use/ # 禁止抓取使用条款页面
这有助于保护网站的法律文件不被搜索引擎索引,确保用户在访问这些页面时遵循网站的法律政策。
以上示例只作为格式参考,配置文件时需要根据你网站的实际情况去写!
robots.txt vs noindex
robots.txt 和 noindex 标签都是用于控制搜索引擎如何与网站互动的工具,但它们在目的、应用方式和效果上存在一些差异:
相同点:
- 目的:两者都旨在控制搜索引擎对网站内容的处理,帮助网站管理员管理其网站在搜索结果中的呈现(是否索引)。
- 限制:它们都是基于爬虫的自愿遵守,大多搜索引擎爬虫会执行这些指令,但不是绝对强制的。
不同点:
- 控制层面:
robots.txt位于网站级别,控制搜索引擎爬虫对整个网站或特定目录的访问权限。noindex是页面级别的元标签,控制搜索引擎是否索引特定的单个页面。
- 应用方式:
robots.txt是一个存储在网站根目录的文本文件,通过设置不同的规则来限制爬虫。noindex是一个HTML标签,需要直接添加到页面的<head>部分。
- 效果:
robots.txt阻止爬虫抓取页面,但如果页面已经被索引,它仍可能出现在搜索结果中(但不会显示元描述)。noindex阻止搜索引擎索引页面,如果页面已经被索引,添加noindex标签后,搜索引擎通常会在下次抓取时从搜索结果中移除该页面。
- 使用场景:
robots.txt适用于需要阻止爬虫访问整个目录或大量页面的场景,如测试环境、私密数据等。noindex适用于需要精细控制单个页面是否被索引的场景,如重复内容页、临时页面、或那些不符合网站质量标准的内容。
- 搜索引擎处理优先级:
- 搜索引擎在抓取网站时首先查看
robots.txt。 - 然后在处理单个页面时再检查
noindex标签。
- 搜索引擎在抓取网站时首先查看
详细了解noindex 标签。

网站先被索引后让robots屏蔽谷歌展示效果
如何编写和提交 robots.txt 文件
如何编写robots.txt文件:
- 创建
robots.txt文件:- 使用文本编辑器(如记事本、Sublime等)创建一个新文本文件。
- 将文件命名为
robots.txt(全小写)。
- 编写规则:
User-agent:指定规则适用的爬虫,如Googlebot,“*”代表所有搜索引擎。Disallow:指定不允许爬虫访问的路径,以斜杠/开头。Allow:指定允许爬虫访问的路径,通常与Disallow结合使用。Sitemap:提供网站地图的URL,帮助搜索引擎发现网站内容。
- 保存文件:
- 使用UTF-8编码保存文件,避免使用富文本格式。
- 网站只能有 1 个 robots.txt 文件。
示例robots.txt文件:
User-agent: Googlebot #对谷歌爬虫的指令
Disallow: /nogooglebot/ #不允许索引/nogooglebot/目录下的内容
User-agent: * #对所有遵守协议的搜索引擎的指令
Allow: / #允许抓取索引所有网页
sitemap: https://www.example.com/sitemap.xml #站点地图地址
如何提交robots.txt到搜索引擎:
- 上传
robots.txt文件:- 将
robots.txt文件上传到网站根目录。(根据建站方式不同文件上传方法也有多种,可以根据自身情况搜索攻略或提交给技术解决) - 确保文件可通过
https://www.example.com/robots.txt访问。
- 将
- 测试
robots.txt文件:- 在浏览器中访问
https://www.example.com/robots.txt,检查文件内容是否正确显示。 - 谷歌站长工具GSC-设置—robots.txt—打开报告检查是否正确。
- 必应,百度的站长工具中也有类似测试的工具。
- 在浏览器中访问
- 等待搜索引擎更新:
- 搜索引擎会自动检测
robots.txt文件的更新,并按照新规则抓取网站。
- 搜索引擎会自动检测

谷歌站长工具测试robots.txt报告
SEO如何利用robots.txt:
- 建站期保护:建站时网站页面将会频繁改变,这个时期可以全面禁止搜索引擎抓取网站(Disallow: /),避免造成一些过时页面被谷歌索引。
- 控制索引:通过
Disallow规则阻止搜索引擎索引特定页面,将一些不好删除的低质量页面阻止索引,不让它们影响网站整体质量。 - 提升网站表现:将搜索引擎抓取预算集中在网站的高质量内容,提高网站页面的收录比。
- 管理抓取频率:通过
robots.txt中的Crawl-delay指令,控制爬虫访问频率,避免过多爬虫访问使服务器过载。 - 防止内容重复:如果网站上有多个URL指向相同或相似的内容,使用 robots.txt 可以阻止爬虫抓取非首选版本的URL。这有助于避免内容重复问题,确保所有SEO价值集中在首选URL上。
总结
robots.txt 是一个位于网站根目录的文本文件,它指导搜索引擎爬虫确定哪些页面可以抓取。通过设置 User-agent、Disallow、Allow 和 Sitemap 等指令,网站管理员能够控制爬虫的访问权限,优化网站的搜索引擎可见性,同时保护网站的隐私和安全。正确配置 robots.txt 对于提升SEO效果、管理网站资源和提高用户体验有重要作用。
大橘小贴士:
robots.txt文件应始终位于网站根目录。- 规则区分大小写,且路径必须在网站根目录。
Disallow规则不阻止搜索引擎显示已索引的页面,但会阻止未来抓取。
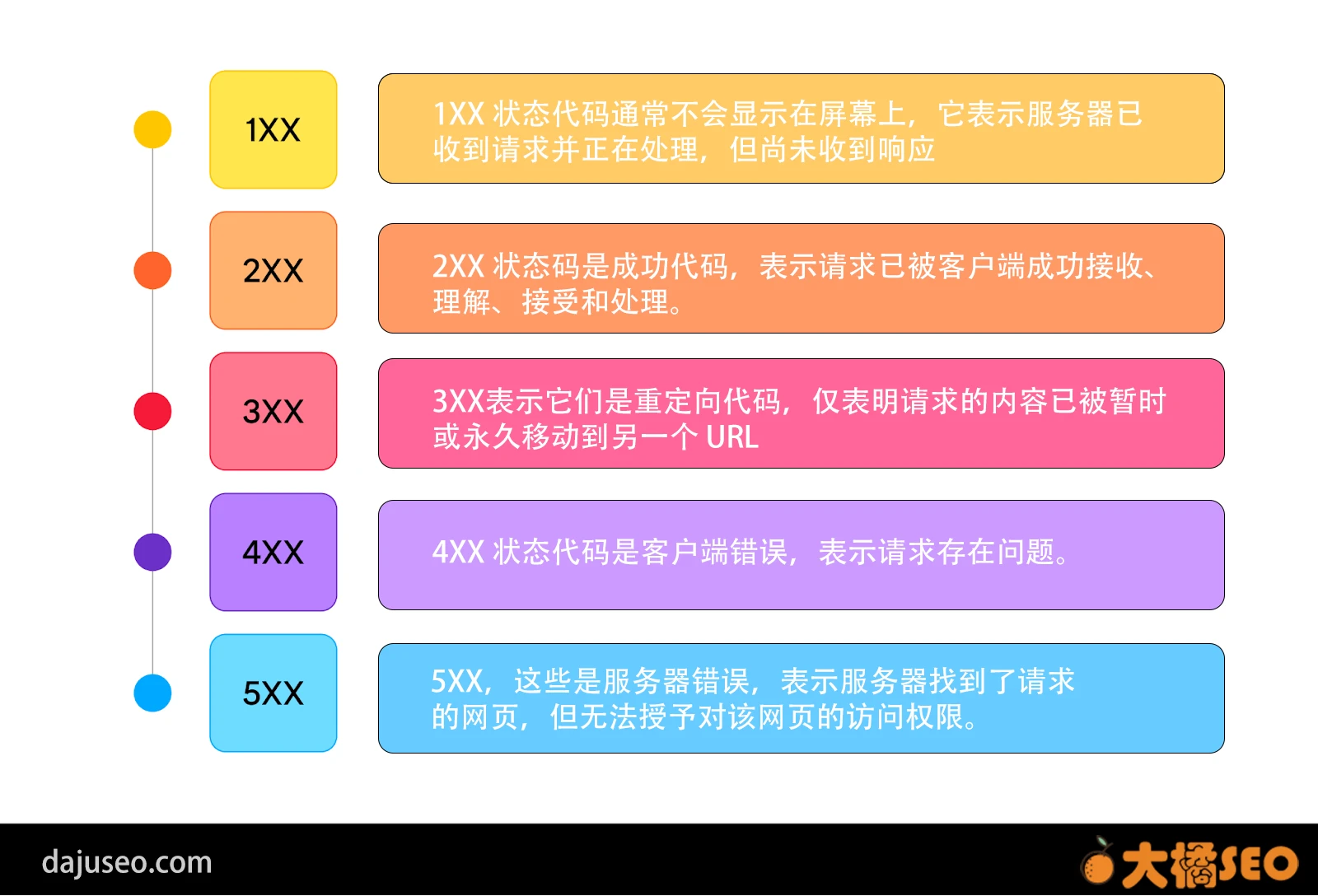
SEO必备HTTP状态码常识完整指南

什么是重定向 | 301重定向的SEO优化
什么是robots.txt?如何配置robots.txt 及其SEO用法 | 详细指南

